tokです。
ライフスタイルの変化に応じて、悩みって変わっていきますよね。
自分が経験してきたものだと、当時のことを思い出せばなんとなく気持ちがわかるものですが、
将来のものだったり、異性のものだと考えが及ばないこともあるのではないかと思います。
今回、総務省統計局が公開しているデータセット、平成25年 国民生活基礎調査(健康票)より年代ごとの悩み/ストレスの原因をグラフにしてみました。
-
国民生活基礎調査の詳細についてはこちら(厚労省のサイトにとびます)
データの元になっている調査票の設問もあります。 - 「世帯人員数(12歳以上),悩みやストレスの有-悩みやストレスの原因(複数回答)-無・性・年齢(5歳階級)別」より
前処理
統計局から取得したCSVファイルは人が読む用になっているので、厳密な(「機械可読な」とも言うらしい)CSV形式となるよう、前もって整形しました。整形後のファイルはこちら
整形の内容は以下のとおり。
- 頭の数行、CSV形式でない部分の削除
- 総数や(再掲)の削除
- 性別で空白になっているところに、男、女を入れる
- 項目整理
Jupyter Labでのグラフ描画
Jupyter Labで以下のコードを実行します。
(実際はたくさん試行錯誤しています・・・)
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv('Downloads/h3212modified.csv')
dfm=df.query("性別=='男'")
plt.title("悩み/ストレス原因(男性)", fontname="Yu Gothic")
plt.xlabel("年齢", fontname="Yu Gothic")
plt.xticks(rotation=90, fontname="Yu Gothic")
dfm2 = dfm.iloc[:,:-5]
y = dfm2.iloc[:,2:].T.to_numpy()
percent = y / y.sum(axis=0).astype(float) * 100
color_list = list(plt.get_cmap("tab20").colors)
plt.stackplot(dfm2.年齢, percent, labels=dfm2.columns[2:].tolist(), colors=color_list)
ax=plt.gca()
handles, labels = ax.get_legend_handles_labels()
plt.legend(handles[::-1], labels[::-1], bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=18, prop={"family":"Yu Gothic"})
「その他」「わからない」「不詳(あり)」「悩みやストレスなし」「不詳(ありなし)」は除外しています。(dfm.iloc[:,:-5]のところ)
苦労したところ
- 日本語表示(fontnameやpropで指定)
- 100%積み上げ面グラフになるように前処理(percentのところ)
- 凡例を上下逆に表示(handles, labels -1のところ)
- stackplotでのカラーマップ指定(color_listのところ)
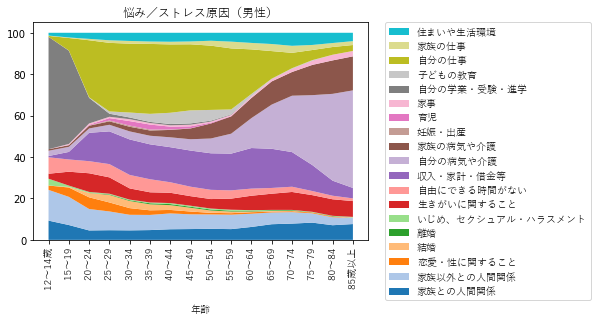
結果 {.wp-block-heading}

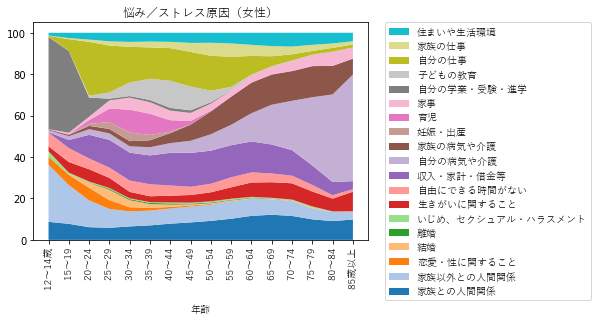
女性版は上のコードの「男」を「女」にすればOKです。
こうして見ると、働く世代の男性は仕事や収入で悩んでいて、女性はそれに加えて子どもの教育や家事、育児、家族の病気や介護など多くの悩み/ストレス原因があることがわかりますね。
また、男性より女性のほうが人間関係で悩んでいる人が多いみたいです。
60超えるあたりでは自分の病気に悩むことになりそうですね。
そうならないように健康的な生活を心がけたいものです(自戒)。
「悩み/ストレス」とは逆に、「楽しみ/生きがい」のデータがあれば見てみたいな。